

Crawling, Analyzing and Visualizing a Friendly Wordle Competition Data
Learn about scraping and cleaning Tweets as well as analyzing and visualizing data!




1. Introduction
• What is Wordle?

Wordle is the biggest word game of 2022. It was created by Josh Wardle, with the simple goal of entertaining his word-game fanatic partner**. The premise of the game is quite simple: Every day, you are given a single puzzle with a hidden 5-digit word and only 6 tries to uncover it.
Once a guess has been made, the game gives clues about what the hidden word is. There are three types of clues:
Gray letter: Does not appear in the word
Yellow letter: Appears in the word, but in another position
Green letter: Appears in the word and in the correct position
Thus, we want all letters to turn green within 6 tries to win the game!
• What did we do?
We enjoyed playing Wordle as a group of three close friends. We started a Twitter thread and shared our Wordle results with each other every day for over 2 months. We played OG Wordle (in English) and Turkish Wordle. There were around 60 days, on which all three of us solved the same puzzle. That's some data! One of us is a software engineer and she thought it would be interesting to scrape this Wordle data from Twitter and perform data analysis on it. Another of one us, who is an architect, visualized the data analysis results in a beautiful way using the color scheme of Wordle!
In the following chapters, we will describe the technical steps of this project and share our results. By using the code here, you can analyze the Wordle competition project for you and your friends!
2. Data Scraping from Twitter
If you do not have thousands of tweets to scrape, and you and your friends all have public Twitter accounts, you can scrape with ease (in two steps!) using snscrape library on Python!
The first step is to install snsscape by running:
pip3 install snscrape.Run
"snscrape --jsonl --max-results RESULT_NUM twitter-search "Wordle from:@USER_NAME"> FILE_NAME.json" on the command line to scrape tweets of the user withUSER_NAMEincluding the word "Wordle". Here,RESULT_NUMis the limit on the number of tweets scraped.
Things get a little more complicated if at least one of your friends has a private Twitter account. You cannot then use snscrape because you need to authenticate! We will explain the details of that process in the next blog post, stay tuned!
3. Data Cleaning
We now have data in a dictionary list format. An example scraped tweet is the following:

The text in bold here constitutes the tweet! Thus we scrape the fields of json with the tag "content". We also need to strip certain characters from the tweet and get the relevant part of it. The first step is to write a function that only extracts relevant emojis from the tweet, which are the emojis corresponding to Wordle tiles.
#Import required libraries
import json
import emoji
def extract_emojis(s):
s2 = "".join(c for c in s if emoji.is_emoji(c))
s3 = s2
for i in range(len(s2)):
if (
s2[i].encode("utf8") != b"\xf0\x9f\x9f\xa6"
and s2[i].encode("utf8") != b"\xf0\x9f\x9f\xa7"
and s2[i].encode("utf8") != b"\xe2\xac\x9c"
and s2[i] != "\u2b1c"
and s2[i] != "\ud83d"
and s2[i] != "\udfe7"
and s2[i] != "\u2b1b"
and s2[i] != "\udfe6"
and s2[i].encode("utf8") != b"\xf0\x9f\x9f\xa9"
and s2[i].encode("utf8") != b"\xf0\x9f\x9f\xa8"
and s2[i].encode("utf8") != b"\xe2\xac\x9c"
and s2[i].encode("utf8") != b"\xf0\x9f\x9f\xa8"
):
s3 = s3.replace(s2[i], "")
return s3Then, using this helper function, we traverse all the tweets that we scraped from a person's timeline and extract the relevant information, namely which Wordle day the game was played, the pattern of the guess, and the number of guesses used. We will then use the number of guesses used to develop a scoring mechanism. More on that in the next section!
def categorize_days_tweets(path):
days_vs_tweet = {}
for lines in open(path, "r"):
line = json.loads(lines)
if "/6" in line["content"]:
for t in range(len(line["content"])):
if (line["content"][t] == "2" and line["content"][t + 1] != "/"): # We only played on Wordle days between 200-300
day = "".join([line["content"][t],line["content"][t + 1],line["content"][t + 2]])#compute Wordle day
days_vs_tweet[day] = (extract_emojis(line["content"]),
line["content"][t + 4],
)
break
return days_vs_tweet
We would like to note that this is a pattern detector for generic Wordle tweets of the following form.
Some text at the top or at the bottom of the Wordle pattern is removed by this code. However, if you or your friends interfered with the generic pattern somehow or if you played Wordle in a different language, you need to write your own parser.

The data is in the format that we want. We can now analyze it!
4. Data Analysis
• Scoring system
If you get the word right in fewer guesses compared to your opponent, you should definitely get more points for a given round of the game. Therefore, we develop a simple scoring system where we basically use the number of guesses until the word is found as the score for that particular game. If the player is unable to find the word within 6 guesses, we give that player the score 7, indicating a failure of that round.
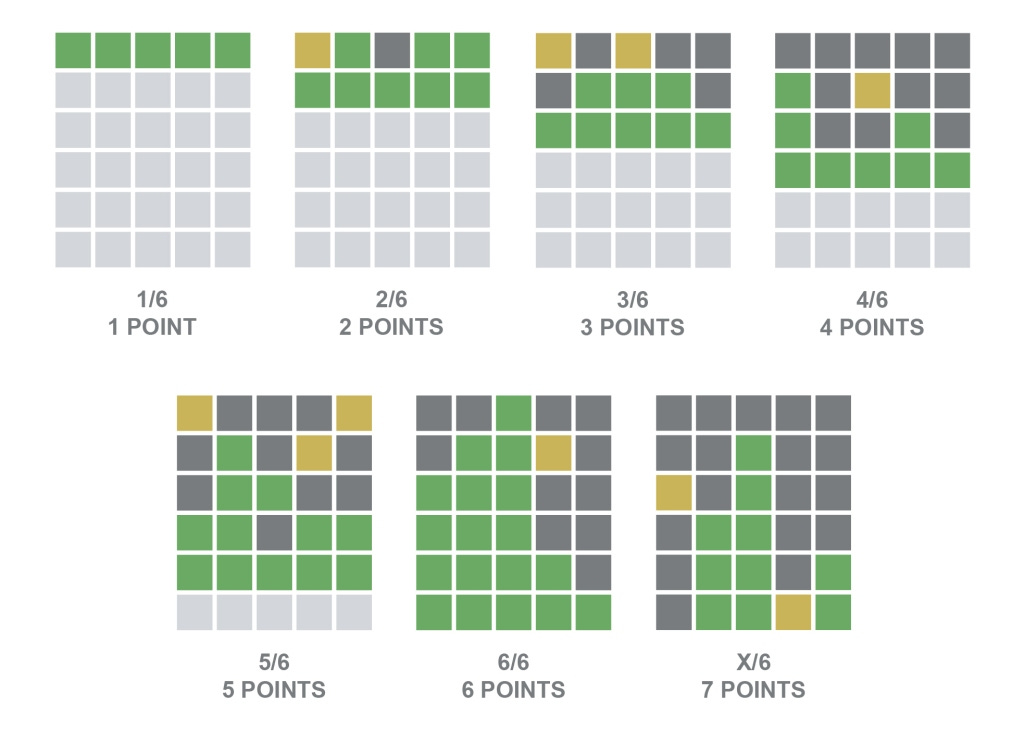
In this scoring system, higher scores constitute worse outcomes. The overall score of a player is computed as their average round score.
• Computing the scores
Here, we will assume that we have already computed the days versus patterns/scores dictionaries of all players, as described in Section 3, and stored them in a list of dictionaries called patterns. Now, we will go over this dictionary and compute the much anticipated scores!
Since we can only fairly compare rounds that take place on the same day, we first need to find the days when all players played the round.
days = []
#patterns is defined somewhere around here as described above
for i in range(200, 300): #We only played on Wordle days between 200-300
days.append(str(i))
for i in range(len(patterns)):
days = list(set(patterns[i].keys()) & set(days))Finally, we can traverse over the dictionaries holding the scores of the players on the common days and compute their scores!
score_counts = []
for i in range(len(patterns)):
score_counts.append(0)
for i in range(len(patterns)):
for day in days:
if patterns[i][day][1] != "X":
score_counts[i] += int(patterns[i][day][1])
else:
score_counts[i] += 7
final_scores = map(lambda x: x/len(days), score_counts)And that is it for computing the scores! You can do a more detailed analysis of scores, which we will possibly talk about in another post and we *finally* move on to the beautiful visualizations created by the architect in our group!
5. Data Visualization
After compiling the data, we analyzed and translated it into statistics. Based on our scoring system we have determined our winner, it turned out that Arda was the winner in both of the language categories. Big congratulations to Arda!
• Creating Avatars

Once we had our winner, it was time to start visualizing! We started by creating personal avatars to match our faces with the scores. Based on our photographs we simply illustrated ourselves in Adobe Illustrator and created flat vector avatars for each of us and created a winners podium to celebrate the game and the good times we have had.

• Visual Identity
It was essential for us to be true to the simple visual identity of Wordle, we started by analyzing the graphic language of Wordle and produced its color palette. Tones of gray, yellow, and green became our color family. In addition to the classical bar graphics and pie charts, we also decided to use matrixes of colored squares to represent the data and games we played.
We used Adobe Illustrator to translate the data into visuals. For some of the visuals which required copying a great number of squares, we used the architectural modeling software Rhinoceros 3D as it was easier and faster to do so. Then we exported the drawing to Illustrator and matched the graphic design.
• Visualizing the Data
We first grouped the statistics into categories: General stats belonging to the sum of games we played, and our personal statistics.
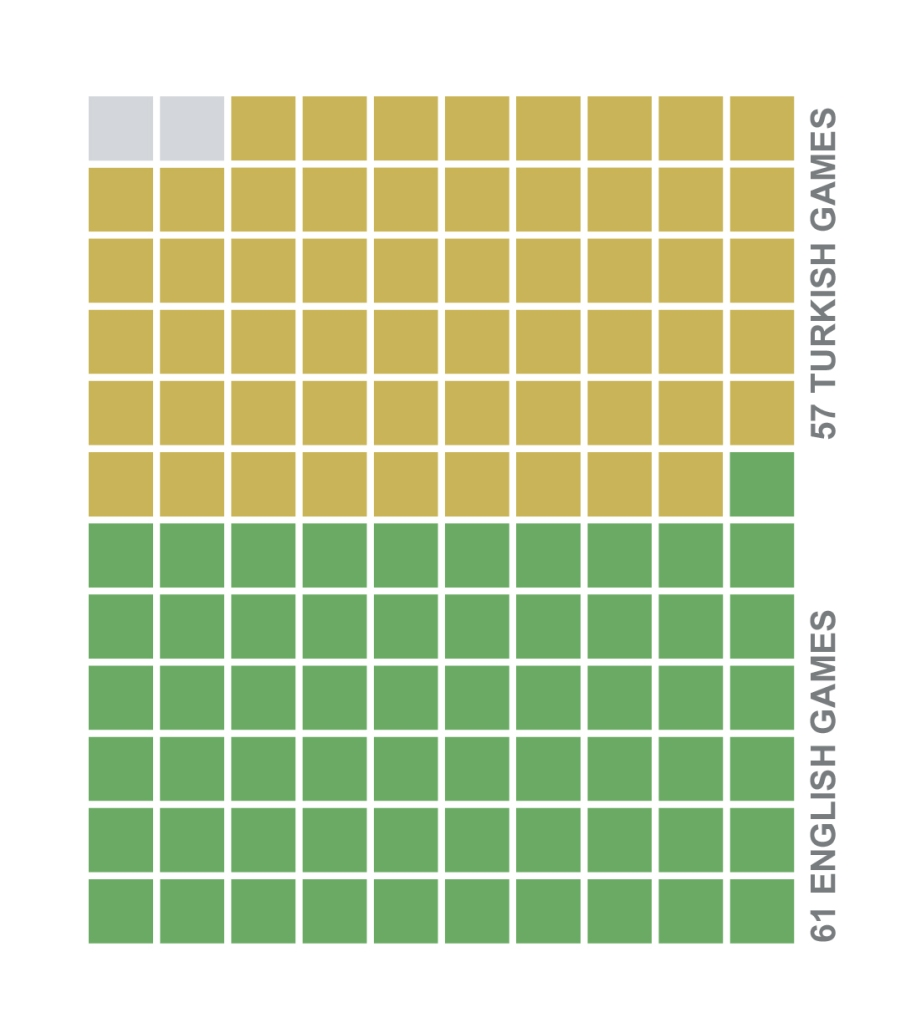
We started with the total number of games we played in both languages to see the bigger picture; a total of 118 days of Wordle, 61 games in English, and 57 games in the Turkish language. We decided to use the colored squares representing each game so that we could easily perceive the number of games proportionate to each other.
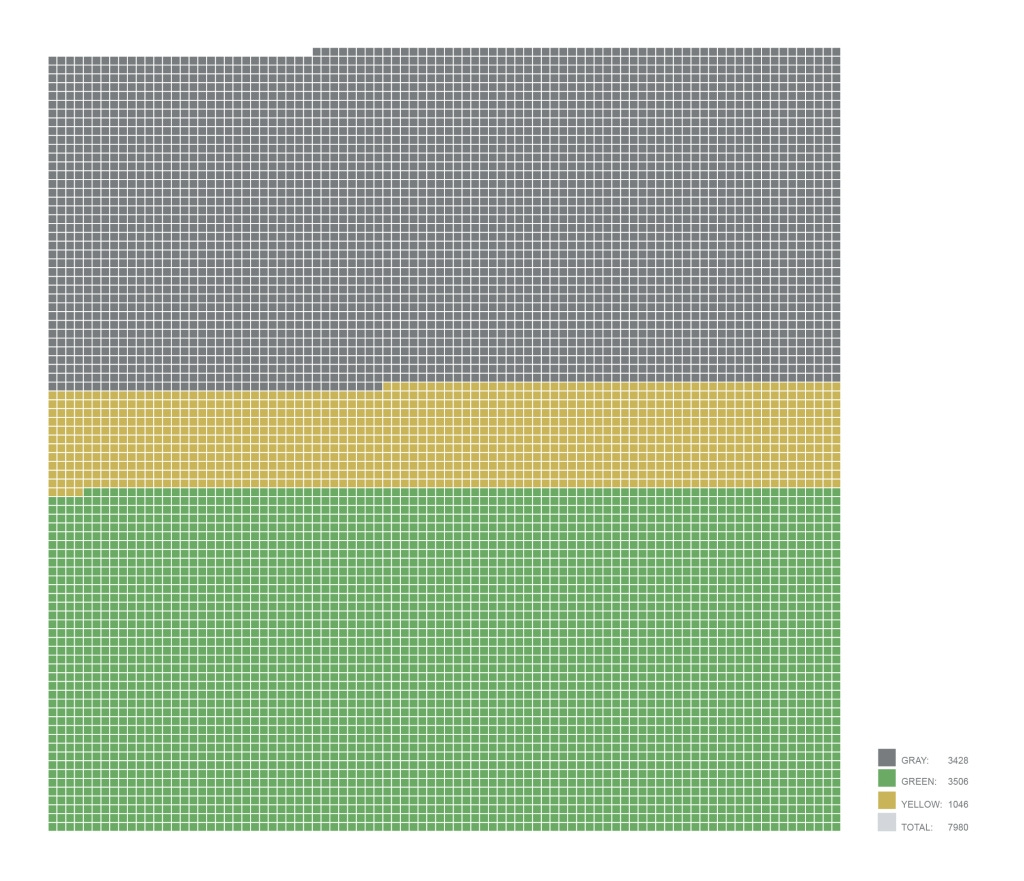
The image above shows the total number of characters based on their colors in all 118 games we played in both languages. Look how little the yellows we used compared to the greens and grays!
• Individual Statistics and Interpretations
We have also looked at our individual statistics in detail in terms of the percentages of games finished per number of guesses. The data categorized in English games shows that Ardammo (Arda) finished most of his games in 4 guesses in %34 of the games, while Irombie (Irem) finished in 6 guesses %29 of the games and Ipqi (Ipek) finished mostly in 4 guesses which corresponded to %30 of her games.
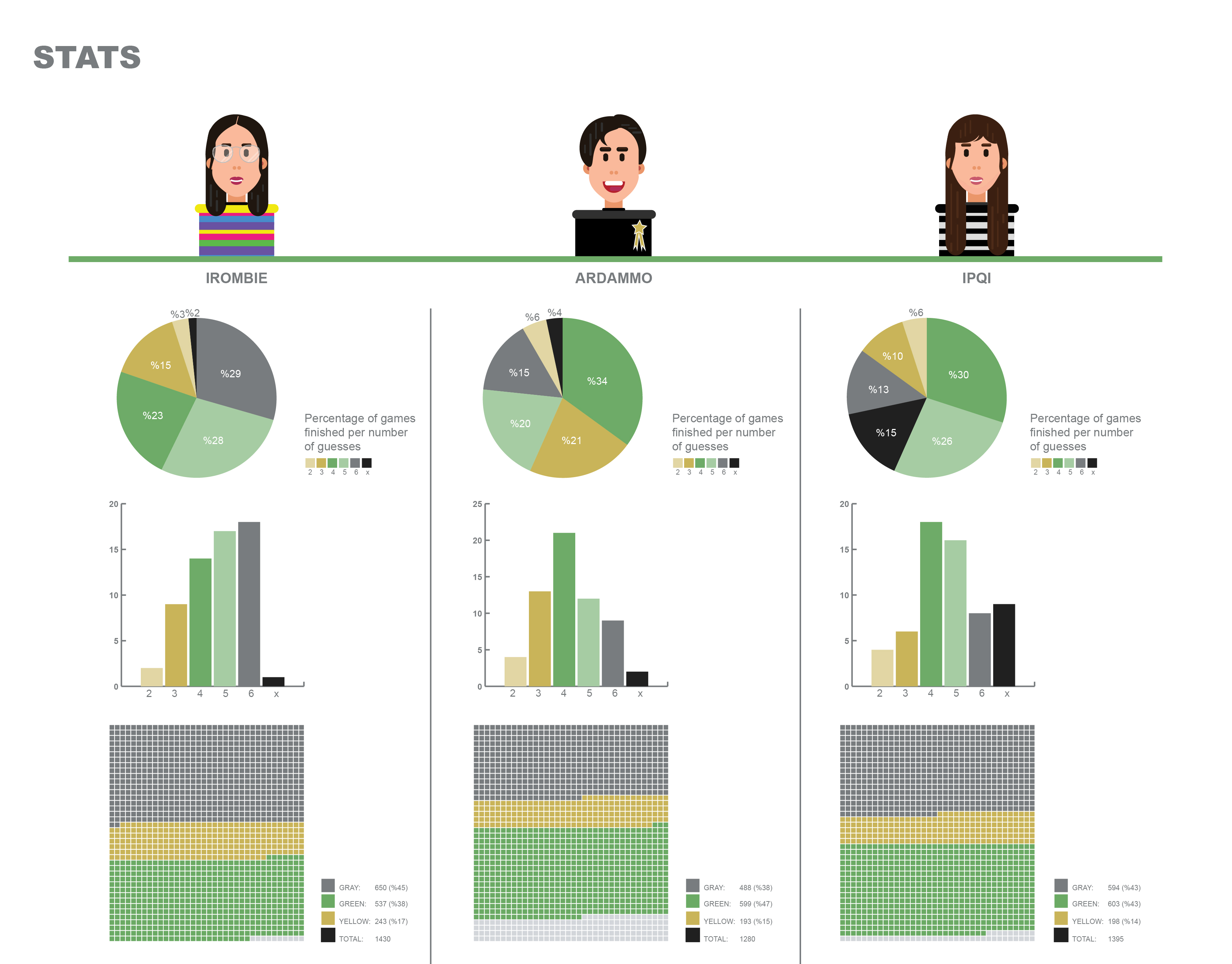
Data also showed that while Irem and Ipek used around 1400 characters in total in English games, Arda used 1280 characters in the English games, combined with this efficiency and the fact that he finished most of his games in 3 or 4 guesses, it is not surprising that Arda becomes the winner in our friendly competition.

We have visualized the same data for the Turkish Wordle games we played and saw that the results show similar behavior in both of the languages (in terms of the games finished per number of guesses along with the total number of characters used.)
• Mega Wordle
Last but not least, we were mesmerized by the colorful festive look of the data after it was compiled and cleaned. So we decided to create a Mega Wordle! We first gathered all the emojis keeping their order, we then matched and color-corrected the blue and orange emojis that resulted from the high contrast mode (that is for improved color vision for colorblind people). After the color correction, we ended up with only the gray, yellow, and green emojis. All the emojis from 354 individual games from our 118 days of Wordle competition, combined in one Mega Wordle!

Epilogue
We would like to thank Josh Wardle and The New York Times Company for creating and publishing Wordle as we had so much fun during the period we had our competition, it became a daily routine for all three of us and brought our lives a kind of consistency. The process was also super exciting to conceptualize and actualize it as a project in all data collecting, analysis, and visualizing phases.
Footnotes
**https://www.cnet.com/culture/internet/wordle-everything-to-know-about-2022s-biggest-word-game/
***There are more fields with detailed user information, but in order to demonstrate only the relevant information, we do not show that part of the data here.
 | A guest post by
|
 | A guest post by
|