Transformers Learn Faster by Taking Notes on the Fly
Increase the pre-training efficiency of transformers by taking notes!



TL;DR If your unsupervised pre-training is taking forever and you need a lightweight solution that will accelerate it, taking notes might be the method you are looking for! This method takes notes of the contextual information of the rare words and incorporates this information as a part of their embeddings on the fly! The solution is lightweight because it does not increase the inference time and does not require an additional pass during training. The experiments demonstrate that this method reduces the pre-training time of large language models by up to 60%.
1. INTRODUCTION

Transformers, which were invented by Google in 2017 [1], have become the go-to architecture for various tasks in many domains, such as natural language processing and computer vision [2-5]. The success of transformers is mainly because they have two amazing properties:
They are phenomenal in grasping the context of words within the bodies of text that they belong to.
They do not process the input sequences in order. Thus, their operations can easily be parallelized.
Equipped with these powerful features, transformers, which drive several state-of-the-art models, such as BERT and GPT-3, have excelled in unsupervised pre-training tasks. In unsupervised pre-training, a large and diverse dataset is used to train the (baseline) model. If someone wishes to fine-tune the base model for a specific task, they can do so by training it with a relatively smaller, task-specific dataset.
Generalization can be achieved with a sufficiently large model that is trained on sufficiently diverse and large data [6, 7]. However, pre-training large models is very time-consuming and costly regarding environmental impacts and monetary resources [8, 9]. Thus, reducing the pre-training time and cost for transformer-based models is an imminent concern for machine learning practitioners. One area with room for improvement is how quickly the model learns the embeddings of the rare words. It has been shown by many works that the embeddings of those words are noisy and not optimized [10-13]. Furthermore, Wu et al. 2021 empirically observe that 20% of all sentences in the corpus contain a rare word, and they propose a “note-taking” approach improves the model’s ability to learn the embeddings of rare words [14]. Impressively, they reduce the pre-training time of well-known large language models (LLMs), such as BERT, by 60%. The approach is called Taking Notes on the Fly (TNF), and we will dive deep into how it works in this blog post!
2. BACKGROUND
Transformers
Wu et al. [14] extends the BERT model [3], which is a transformer-based model with external memory. A transformer is composed of alternating multi-head attention and feed-forward layers. The initial input to the multi-head attention layer is the sum of word embeddings and positional embeddings. Each one-hot encoded token is multiplied with a weight matrix in order to obtain a real-valued non-sparse representation. The weight matrix is learned throughout the training. Because transformers do not process words in order, we also need to provide some information about the token's position in a sentence. This is incorporated into the training by the “positional embedding (encoding)”(PE) vector, composed of sine and cosine pairs.
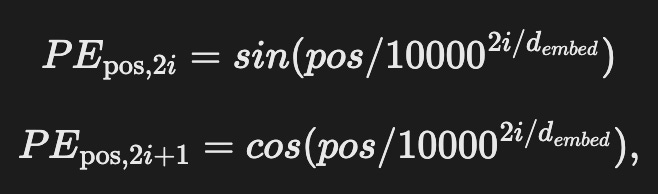
where pos is the token's position in the sentence, d_embed is the embedding dimension of the model, and i refers to the dimension in the PE vector. Note that the positional embeddings do not depend on the meaning of the words but only on their position!
Self-attention mechanism allows the model to relate words in a sentence through a set of learnable queries (Q), key (K), and value (V) vectors. The output of the attention function calculates a compatibility score for each pair of words in the sentence. Mathematically, self-attention can be expressed as
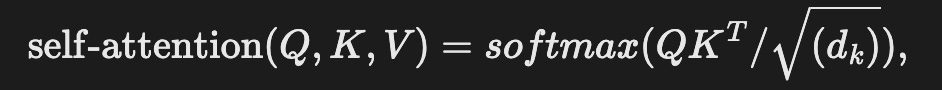
where d_k is the dimension of hidden representations. In order to improve the representational power of the model, [1] proposed a multi-head attention mechanism. In particular, the self-attention function is calculated several times independently; the results are concatenated and linearly projected into the desired dimension.
BERT is a masked language model which uses the transformer architecture. During training time, 15% of the words in the sentence are masked or replaced with a random word. The model learns to predict the words that are masked.
Word Distribution in Texts
The distribution of the words in a natural language corpora follows Zipf’s law [15]; that is, the frequency of the n-th most frequent word is proportional to 1/(n^α), where α<1.
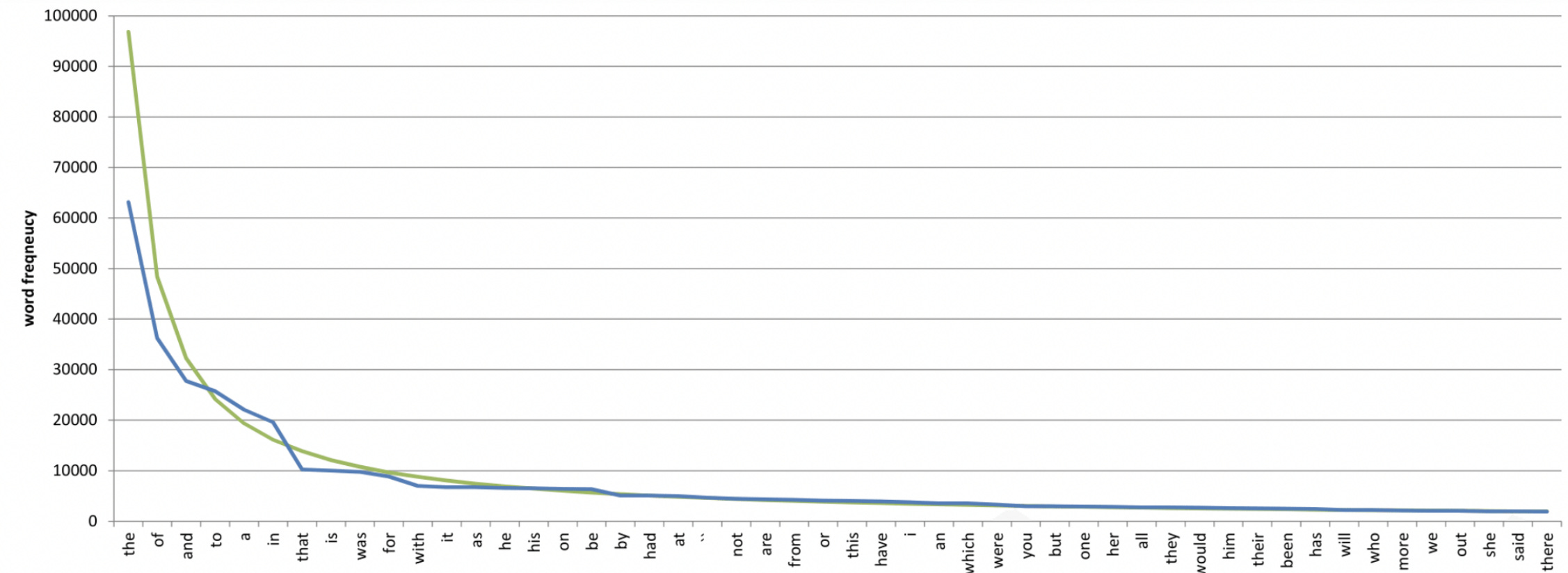
In other words, the number of popular words is much less than that of rare words, yet their frequency is much larger. This harms the pre-training of LLMs, causing sparse and inaccurate optimization of neural networks since rare words are much more likely to generate noisy and low-quality embeddings [17].
3. RELATED WORK
Pre-training of LLMs has become a burden regarding training time and power consumption. Still, it is essential for almost every downstream task in NLP. Several studies address this computational cost in terms of altering the model or utilizing the weight distribution of neural networks’ layers. Particularly, [18] added a discriminator to predict whether each word in the sentence the generator completes is correct. Another important work arose after the observation that the attention distributions of the top and bottom layers are quite similar. [19] proposed an iterative algorithm that doubles the number of layers after each training episode.
The efficiency of pretraining LLMs has been shown to have increased; still, the heavy-tailed distribution of words in natural language corpora is an obstacle to further development [8]. The note-taking approach positively impacts learning performance in humans [20]. This idea inspired studies on contributing to training efficiency [14] and increasing performance in downstream tasks [21-24].
It is shown that the frequency of words affects the embeddings. Additionally, most of the rare words’ embeddings are close to each other in embedding space independent from their semantic information while the neighbors of frequent words are the ones that have similar meanings [11]. Initial studies mainly used subword information to encode semantic information; this approach is shown to be valuable for morphologically rich languages [25-27]. Recently, this problem is also addressed by using adversarial training where a discriminator classifies each word as ‘frequent’ or ‘rare’, allowing semantic information to be encoded.
3. METHODOLOGY
Because learning the embeddings of rare words is arduous, it takes a lot of training epochs for the model to compensate for the resulting loss in quality. Thus, the authors propose keeping a third type of embedding (besides the word embeddings and positional embeddings), which is designed to retain additional information about the rare words. This embedding type can be considered as taking notes on the contextual information of these rare words as the training progresses, is also called the note dictionary, and is updated as the training progresses.
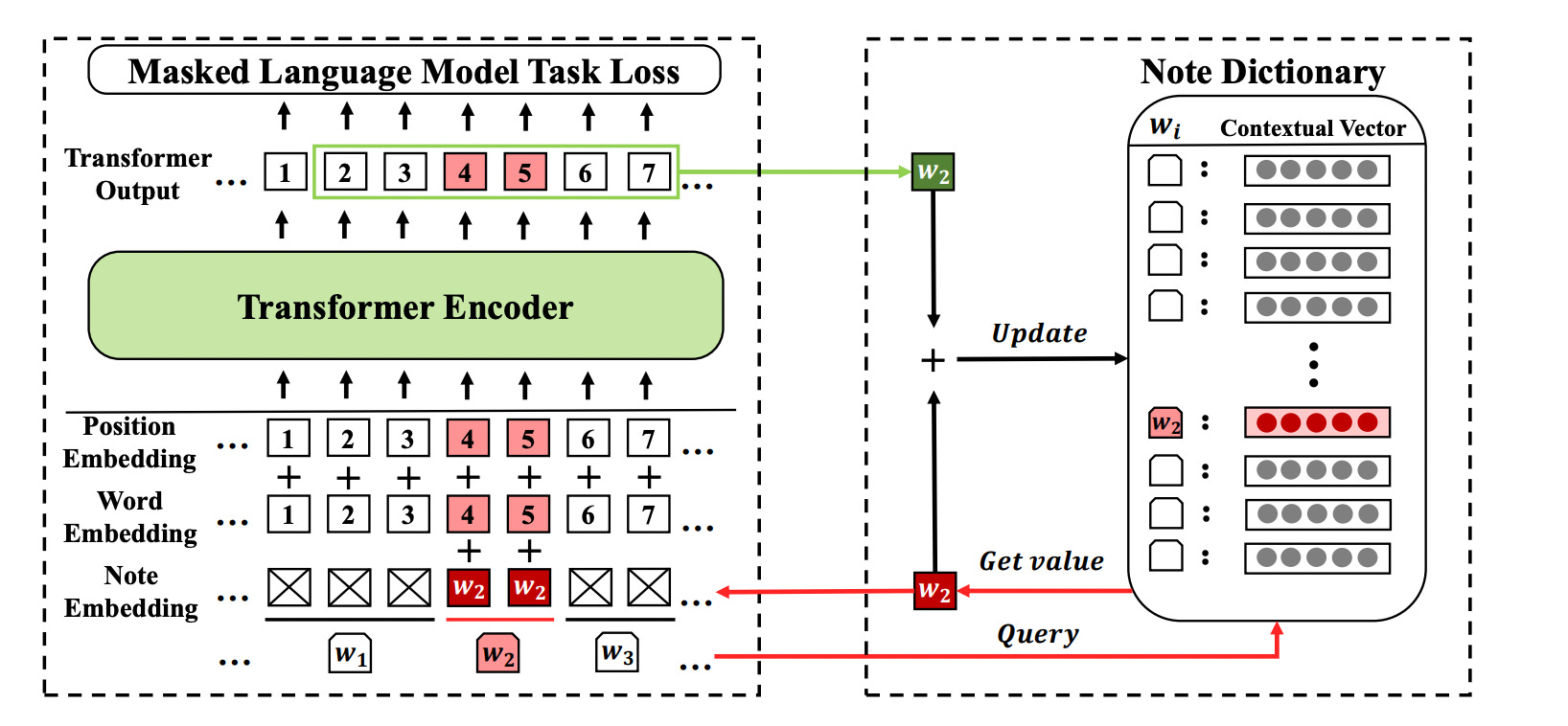
At this point, we assume that the text has already been pre-processed using Byte Pair Encoding (BPE), a popular method used as part of the text embedding process for NLP tasks [28]. In BPE1, each word is represented as a concatenation of sub-word units selected according to how much each unit occurs in the given text. For example, if the subword "pre" occurs in the text frequently, it will be represented with a single character, such as "X" in this encoding. This way, the textual data is compressed and manageable. Also, because each sub-word unit gets its own embedding, we get a hybrid approach between word-level and character-level embeddings. Therefore, embedding each word might very well comprise multiple consecutive tokens. With this information in mind, let us walk through the steps of note-taking!
Randomly initialize the note dictionary, NoteDict.
Determine a window size (2k as denoted in the paper) corresponding to the number of surrounding tokens whose embedding will be included in the note.
Determine a discount factor, Γ, which is between 0 and 1.
For each word w in the training corpora, check if the word is a rare word or not. If it is rare, mark the index of the starting and ending sub-word tokens of the word with s and t, respectively.
Compute the output of the transformer encoder on the input embeddings. The resulting embeddings will be composed of a d-dimensional vector per token.
Given a sequence of tokens x with w in it, sum the d-dimensional input embedding vectors of all tokens located between indices s-k and t+k and divide this sum by 2k+t-s, namely, the number of tokens within that interval. The resulting vector is the note of w taken for sequence x, NoteDict(w,x). Mathematically, we have,
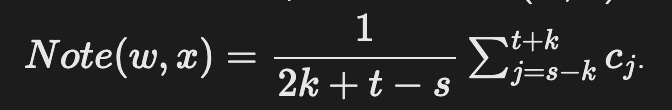
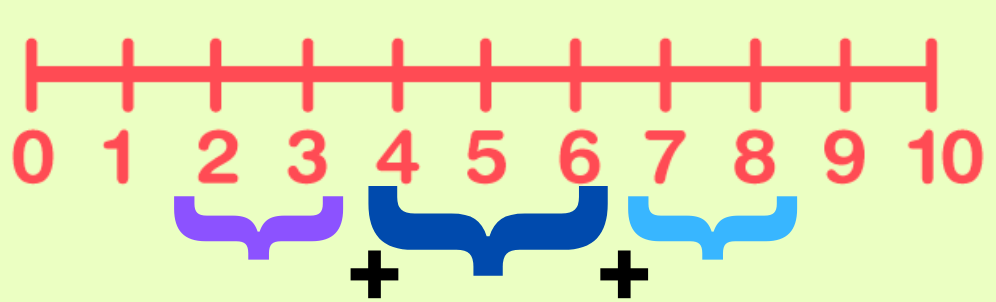
Let us also visualize this process with an example 👇🏻

This figure demonstrates contextual embedding vectors at which locations will be selected and summed with an example. This line represents the indices of a sequence of length 11. Let us assume that the rare word is contained within tokens 4 to 6, and k=2, which makes the window size 2k=4. Thus, we sum the tokens at locations 4, 5, and 6, as well as 3, 4 (which are the two immediate left tokens), and 7,8 (which are the two immediate right tokens). Finally, we divide each element of the resulting vector by 6, which is the total number of elements in the interval.
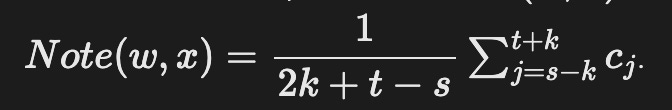
6. To update the note embedding of w, NoteDict(w), take the exponential moving average of its previous value and NoteDict(w,x) using the discount factor. Mathematically, we have
→ NoteDict(w)=(1-Γ)NoteDict(w)+Γ NoteDict(w,x).
This process repeats until all of the sentences are processed this way. Note that this can be achieved on the fly as the model processes each sentence. Now that we have our notes neatly stored in NoteDict let us incorporate them into the training process! We again take the exponential moving average of the sum of the positional and token embeddings (the embedding used in the original transformer paper) with the corresponding NoteDict value using another parameter, λ. In particular, for every word w that occurs in both NoteDict and sequence x, each location corresponding to the word w and its surrounding 2k tokens is set to the weighted sum of the positional and token embeddings with the corresponding NoteDict value. Any other location is set to the sum of the token embeddings and positional embeddings only. The resulting vector will be the input to our model for the next step. Mathematically, for location i, which is an integer between 1 and d, which corresponds to (one of the) tokens of word w in the sequence, we have

4. RESULTS
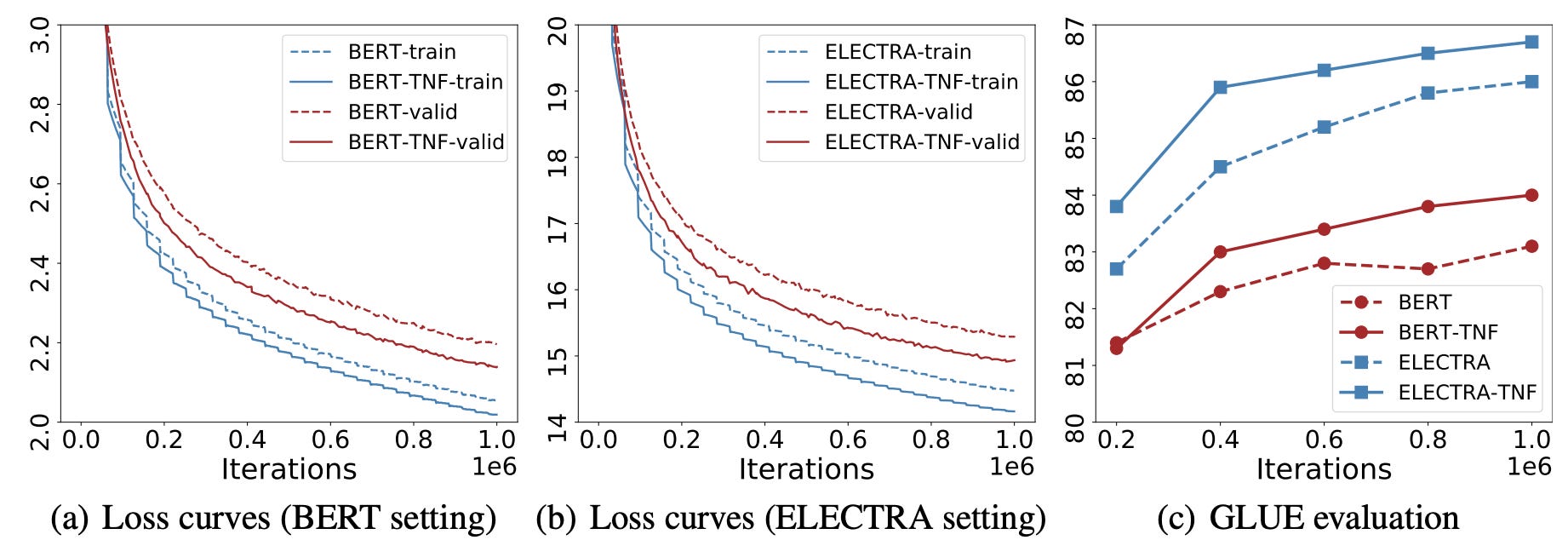
The experiments are conducted on BERT and ELECTRA models. The loss values of the pre-training runs with note-taking decrease significantly faster than vanilla pre-training. Moreover, the models trained while taking notes achieve higher GLUE [29] scores much faster. Additionally, they report that after one million iterations, the GLUE score of the models pre-trained with notes is superior to their counterparts trained without notes. Finally, they report that when it took one model with note-taking to reach a certain GLUE score of around 100.000 training iterations, it took the model around 400.000 training iterations to reach that same score without notes. That is a 60% improvement in training time to reach the same performance!
5. CONCLUSION
The ever-increasing data sizes, enlarging models, and hardware resources are some of the major factors in the current success of LLMs. However, this also means immense power consumption and carbon emission2. Because pre-training of LLMs is the most computationally intensive phase of a natural language task, efficient pre-training is the concern of this paper. Knowing that the heavy-tailed distribution of word frequencies in any natural language corpora may hinder pre-training efficiency, improving data utilization is crucial. Therefore, the authors propose a memory extension to the transformer architecture: “Taking Notes on the Fly”. TNF holds a dictionary where each key is a rare word. The values are the historical contextual information which is updated each time the corresponding word is encountered. The dictionary is removed from the model during the inference phase. TNF reduces the training time by 60% without any reduction in performance.
REFERENCES
Attention is all you need
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L. and Polosukhin, I., 2017. Advances in neural information processing systems, Vol 30.An image is worth 16x16 words: Transformers for image recognition at scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S. and others,, 2020. arXiv preprint arXiv:2010.11929.Bert: Pre-training of deep bidirectional transformers for language understanding
Devlin, J., Chang, M., Lee, K. and Toutanova, K., 2018. arXiv preprint arXiv:1810.04805.Improving language understanding by generative pre-training
Radford, A., Narasimhan, K., Salimans, T., Sutskever, I. and others,, 2018. OpenAI.Language models are few-shot learners
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A. and others,, 2020. Advances in neural information processing systems, Vol 33, pp. 1877--1901.Language models are unsupervised multitask learners
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I. and others,, 2019. OpenAI blog, Vol 1(8), pp. 9.Memorization without overfitting: Analyzing the training dynamics of large language models
Tirumala, K., Markosyan, A.H., Zettlemoyer, L. and Aghajanyan, A., 2022. arXiv preprint arXiv:2205.10770.Energy and policy considerations for deep learning in NLP
Strubell, E., Ganesh, A. and McCallum, A., 2019. arXiv preprint arXiv:1906.02243.bert2bert: Towards reusable pretrained language models
Chen, C., Yin, Y., Shang, L., Jiang, X., Qin, Y., Wang, F., Wang, Z., Chen, X., Liu, Z. and Liu, Q., 2021. arXiv preprint arXiv:2110.07143.Learning to compute word embeddings on the fly
Bahdanau, D., Bosc, T., Jastrz{\k{e}}bski, S., Grefenstette, E., Vincent, P. and Bengio, Y., 2017. arXiv preprint arXiv:1706.00286.Frage: Frequency-agnostic word representation
Gong, C., He, D., Tan, X., Qin, T., Wang, L. and Liu, T., 2018. Advances in neural information processing systems, Vol 31.Constrained output embeddings for end-to-end code-switching speech recognition with only monolingual data
Khassanov, Y., Xu, H., Pham, V.T., Zeng, Z., Chng, E.S., Ni, C. and Ma, B., 2019. arXiv preprint arXiv:1904.03802.It's not just size that matters: Small language models are also few-shot learners
Schick, T. and Schutze, H., 2020. arXiv preprint arXiv:2009.07118.Taking notes on the fly helps language pre-training
Wu, Q., Xing, C., Li, Y., Ke, G., He, D. and Liu, T., 2021. International Conference on Learning Representations.Selected studies of the principle of relative frequency in language
Zipf, G.K., 1932. Harvard university press.Logarithmical: Zipf’s Law and the mathematics of punctuation [link]
Houston, K..Representation degeneration problem in training natural language generation models
Gao, J., He, D., Tan, X., Qin, T., Wang, L. and Liu, T., 2019. arXiv preprint arXiv:1907.12009.Electra: Pre-training text encoders as discriminators rather than generators
Clark, K., Luong, M., Le, Q.V. and Manning, C.D., 2020. arXiv preprint arXiv:2003.10555.Efficient training of bert by progressively stacking
Gong, L., He, D., Li, Z., Qin, T., Wang, L. and Liu, T., 2019. International conference on machine learning, pp. 2337--2346.Optimising the use of note-taking as an external cognitive aid for increasing learning
Makany, T., Kemp, J. and Dror, I.E., 2009. British Journal of Educational Technology, Vol 40(4), pp. 619--635. Wiley Online Library.Memory Augmented Lookup Dictionary based Language Modeling for Automatic Speech Recognition
Feng, Y., Tu, M., Xia, R., Huang, C. and Wang, Y., 2022. arXiv preprint arXiv:2301.00066.Entities as experts: Sparse memory access with entity supervision
Fevry, T., Soares, L.B., FitzGerald, N., Choi, E. and Kwiatkowski, T., 2020. arXiv preprint arXiv:2004.07202.Retrieval augmented language model pre-training
Guu, K., Lee, K., Tung, Z., Pasupat, P. and Chang, M., 2020. International conference on machine learning, pp. 3929--3938.Generalization through memorization: Nearest neighbor language models
Khandelwal, U., Levy, O., Jurafsky, D., Zettlemoyer, L. and Lewis, M., 2019. arXiv preprint arXiv:1911.00172.Learning Character-level Representations for Part-of-Speech Tagging [HTML]
Santos, C.D. and Zadrozny, B., 2014. Proceedings of the 31st International Conference on Machine Learning, Vol 32(2), pp. 1818--1826. PMLR.Character-aware neural language models
Kim, Y., Jernite, Y., Sontag, D. and Rush, A.M., 2016. Thirtieth AAAI conference on artificial intelligence.Parsimonious morpheme segmentation with an application to enriching word embeddings
El-Kishky, A., Xu, F., Zhang, A. and Han, J., 2019. 2019 IEEE International Conference on Big Data (Big Data), pp. 64--73.Neural machine translation of rare words with subword units
Sennrich, R., Haddow, B. and Birch, A., 2015. arXiv preprint arXiv:1508.07909.GLUE: A multi-task benchmark and analysis platform for natural language understanding
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O. and Bowman, S.R., 2018. arXiv preprint arXiv:1804.07461.A very nice blog post about CO2 emissions: https://towardsdatascience.com/deep-learning-and-carbon-emissions-79723d5bc86e
A very nice blog post about CO2 emissions: https://towardsdatascience.com/deep-learning-and-carbon-emissions-79723d5bc86e
 | A guest post by
|
 | A guest post by
|
🔥💯💯